This document describes a technological improvement I brought to a team in the university of Lausanne (Unil). This team is composed of two professors, one PhD student and one master student. The project is a programming course for first year HEC students, hosted on Jupyterhub, deployed on an on-premise Kubernetes cluster.
I joined the team as a DevOps / Site reliability engineer. The infrastructure is composed of 8 on-premise machines on which a Kubernetes cluster is installed.
There was a problem in this setup on the previous year teaching session, which was when students connected to the platform, their single pods were all scheduled on the same node. The result of this was a slowness.
Since then the cluster has been reinstalled with a new method. So first I wanted to see if the problem was still existing. For this I developped a bot that was simulating a student connexion on a test environment with authentication disabled. The observed behavior was similar to the previous year.
The solution I found to this was to modify the Jupyterhub spawner so that it randomly selects the node on which the single user pods are scheduled.
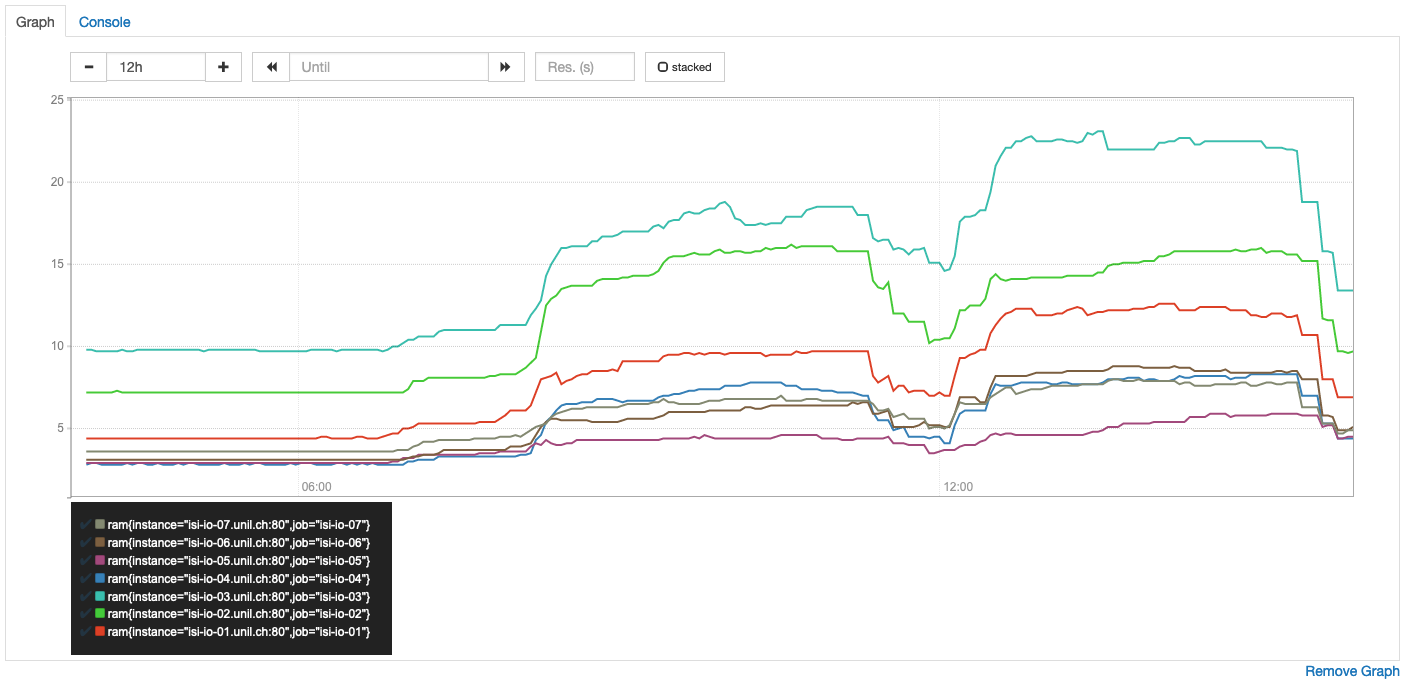
This Prometheus Graph shows the RAM usage with time during the two teaching sessions after my fix (one in the morning and the other in the afternoon). The servers memory usages represented by the blue and green curves are higher than others because machines receive the same load as others but are are less powerful. The red curve represents the Kubernetes active master node, that is why is is more loaded than other servers that appear in the bottom.
This way, the load was correctly balanced across nodes.